
As part of the Developing Data Products class at Coursera, we’ve been encouraged to share our R Shiny apps on twitter using the #myDataProduct hashtag! I tweeted mine and blogged about it already. I’ve also blogged about word clouds in R. And lo and behold, someone did both! @dscorzoni combined Shiny and word clouds into a nifty little app that takes a URL and generates a word cloud from it! How cool!!
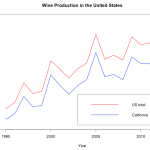
Did you know that over 90% of the wine produced in the United States is made right here in California? I just learned that.
Sometimes, you randomly are in the depths of the internet and you find some data in a hideous table and you just *have* to visualize it! Here’s a brief how-to with some fun data on wine!!

My friend recently asked me how I make word clouds for presentations. Wordle is definitely a good choice. WordPress automatically makes word clouds out of my tags in the sidebar. But sometimes you can’t or don’t want to upload your data to places like WordPress or Wordle and you just want to use R (because you use R for everything else, so why not? Or is that just me?).
In a typical word cloud, word frequency is what determines the size of the word. As of this writing, the word cloud in my side bar (over there →) has “linguistics” and “programming” as clearly the largest words. Tags like “video games,” “language,” and “education” are also pretty big. There are also really small words like “Navajo” and “handwriting.” This reflects the frequency of each tag. Bigger tags are more frequent, so I write about linguistics a lot but not so much about Navajo in particular.

When I enrolled as a freshman in college, I registered as a linguistics major but I had a notion that I would minor in computer science. Computer science seemed interesting and well-paying and I didn’t even know computational linguistics was a thing at the time. I just liked computers. I never had a problem switching between Macs and PCs. I liked to peak inside computers and replace the RAM and things like that. I had poked around with HTML editors. The classes on things like graphic design and artificial intelligence and stuff seemed really cool.
I looked up the prerequisites and found that to minor in CS you had to actually get pretty far in math, at least through Calculus C and one or two courses of Linear Algebra. So, naturally, I signed up for Calculus A my fall term.
Flashback to my first quarter of grad school.
We take turns buying snacks with a $40 budget in my department. It was my turn that week. I bought a lot of snacks. An older grad student comments on all the snacks, and I mention that I found a couple coupons, so I was able to get more snacks than usual.
His response?
“That’s some wicked palatalization you got there!”
Language has a pretty interesting property known as Zipf’s Law. That is, language data (and even subsets of language data) have a Zipfian distribution. There are a small number of highly frequent words, and a large number of highly infrequent words. Moreover, the frequent words tend to be short, grammatical (words that are grammatically required but don’t really mean anything) and the infrequent words tend to be longer, lexical (words like nouns and verbs which have some sort of referent or meaning).
What does this mean? Well, to show you I downloaded all of the English wikipedia (and you can too here). More »